本文首发于公众号:机器感知
Inf-DiT:Upsampling Any-Resolution Image、Vidu、MVDiff、Trio-ViT

Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer

Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is .......
Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models

We introduce Vidu, a high-performance text-to-video generator that is capable of producing 1080p videos up to 16 seconds in a single generation. Vidu is a diffusion model with U-ViT as its backbone, which unlocks the scalability and the capability for handling long videos. Vidu exhibits strong coherence and dynamism, and is capable of generating both realistic and imaginative videos, as well as understanding some professional photography techniques, on par with Sora -- the most powerful reported text-to-video generator. Finally, we perform initial experiments on other controllable video generation, including canny-to-video generation, video prediction and subject-driven generation, which demonstrate promising results.......
Space-time Reinforcement Network for Video Object Segmentation
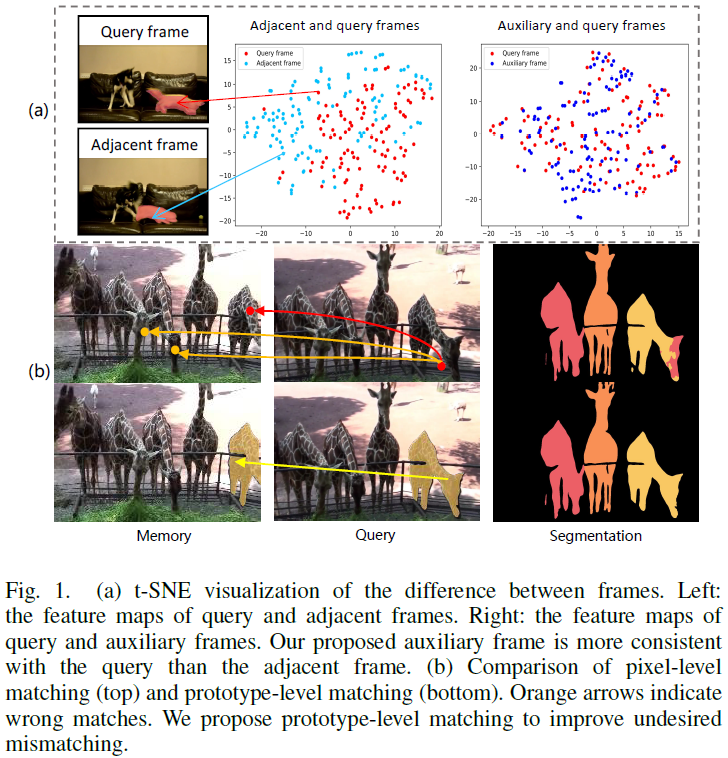
Recently, video object segmentation (VOS) networks typically use memory-based methods: for each query frame, the mask is predicted by space-time matching to memory frames. Despite these methods having superior performance, they suffer from two issues: 1) Challenging data can destroy the space-time coherence between adjacent video frames. 2) Pixel-level matching will lead to undesired mismatching caused by the noises or distractors. To address the aforementioned issues, we first propose to generate an auxiliary frame between adjacent frames, serving as an implicit short-temporal reference for the query one. Next, we learn a prototype for each video object and prototype-level matching can be implemented between the query and memory. The experiment demonstrated that our network outperforms the state-of-the-art method on the DAVIS 2017, achieving a J&F score of 86.4%, and attains a competitive result 85.0% on YouTube VOS 2018. In addition, our network exhibits a high inference sp......
Structured Click Control in Transformer-based Interactive Segmentation
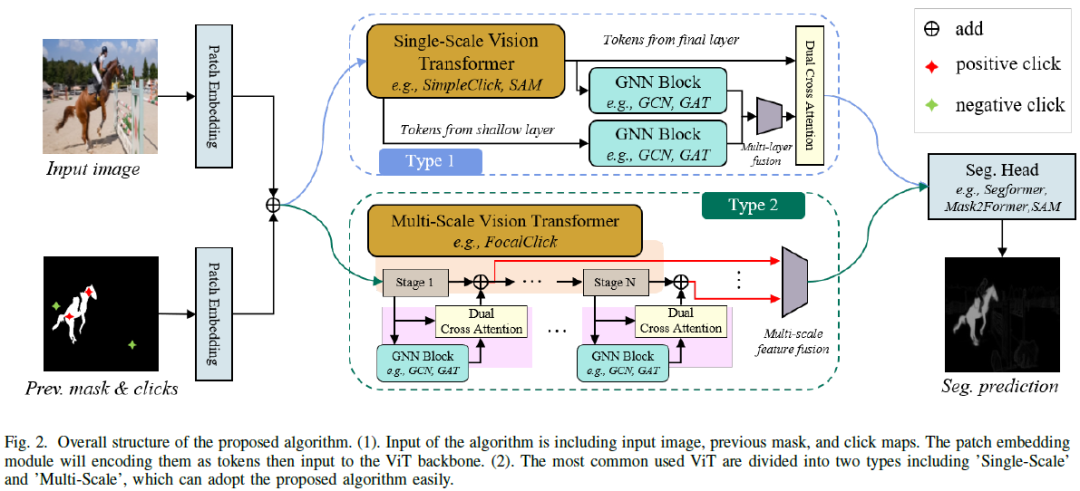
Click-point-based interactive segmentation has received widespread attention due to its efficiency. However, it's hard for existing algorithms to obtain precise and robust responses after multiple clicks. In this case, the segmentation results tend to have little change or are even worse than before. To improve the robustness of the response, we propose a structured click intent model based on graph neural networks, which adaptively obtains graph nodes via the global similarity of user-clicked Transformer tokens. Then the graph nodes will be aggregated to obtain structured interaction features. Finally, the dual cross-attention will be used to inject structured interaction features into vision Transformer features, thereby enhancing the control of clicks over segmentation results. Extensive experiments demonstrated the proposed algorithm can serve as a general structure in improving Transformer-based interactive segmenta?tion performance. The code and data will be released at......
SEED-Data-Edit Technical Report: A Hybrid Dataset for Instructional Image Editing

In this technical report, we introduce SEED-Data-Edit: a unique hybrid dataset for instruction-guided image editing, which aims to facilitate image manipulation using open-form language. SEED-Data-Edit is composed of three distinct types of data: (1) High-quality editing data produced by an automated pipeline, ensuring a substantial volume of diverse image editing pairs. (2) Real-world scenario data collected from the internet, which captures the intricacies of user intentions for promoting the practical application of image editing in the real world. (3) High-precision multi-turn editing data annotated by humans, which involves multiple rounds of edits for simulating iterative editing processes. The combination of these diverse data sources makes SEED-Data-Edit a comprehensive and versatile dataset for training language-guided image editing model. We fine-tune a pretrained Multimodal Large Language Model (MLLM) that unifies comprehension and generation with SEED-Data-Edit. T......
Simple Drop-in LoRA Conditioning on Attention Layers Will Improve Your Diffusion Model
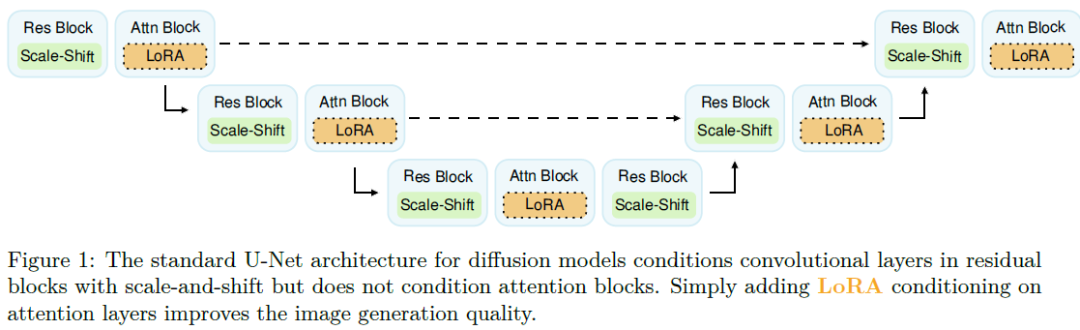
Current state-of-the-art diffusion models employ U-Net architectures containing convolutional and (qkv) self-attention layers. The U-Net processes images while being conditioned on the time embedding input for each sampling step and the class or caption embedding input corresponding to the desired conditional generation. Such conditioning involves scale-and-shift operations to the convolutional layers but does not directly affect the attention layers. While these standard architectural choices are certainly effective, not conditioning the attention layers feels arbitrary and potentially suboptimal. In this work, we show that simply adding LoRA conditioning to the attention layers without changing or tuning the other parts of the U-Net architecture improves the image generation quality. For example, a drop-in addition of LoRA conditioning to EDM diffusion model yields FID scores of 1.91/1.75 for unconditional and class-conditional CIFAR-10 generation, improving upon the baseli......
KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization
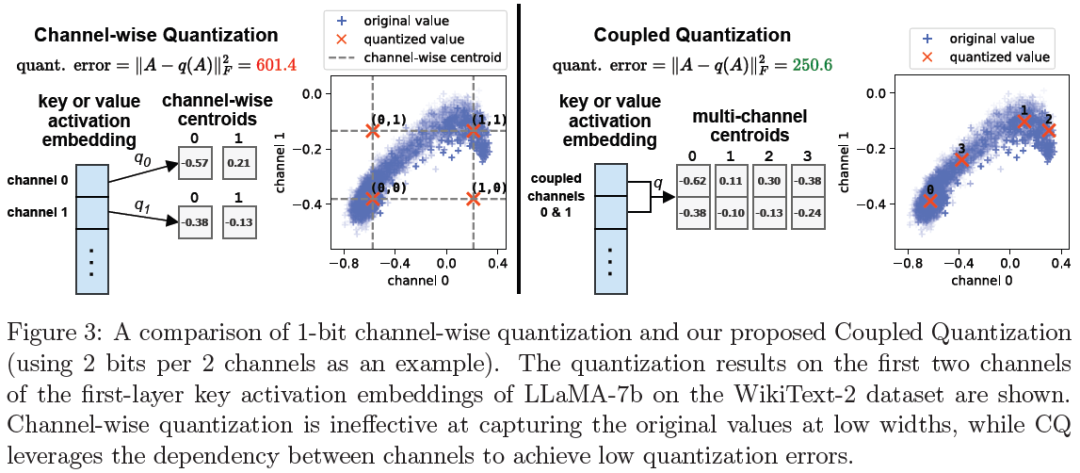
Efficient deployment of Large Language Models (LLMs) requires batching multiple requests together to improve throughput. As the batch size, context length, or model size increases, the size of the key and value (KV) cache can quickly become the main contributor to GPU memory usage and the bottleneck of inference latency. Quantization has emerged as an effective technique for KV cache compression, but existing methods still fail at very low bit widths. We observe that distinct channels of a key/value activation embedding are highly inter-dependent, and the joint entropy of multiple channels grows at a slower rate than the sum of their marginal entropies. Based on this insight, we propose Coupled Quantization (CQ), which couples multiple key/value channels together to exploit their inter-dependency and encode the activations in a more information-efficient manner. Extensive experiments reveal that CQ outperforms or is competitive with existing baselines in preserving model qual......
MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View

Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.......
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
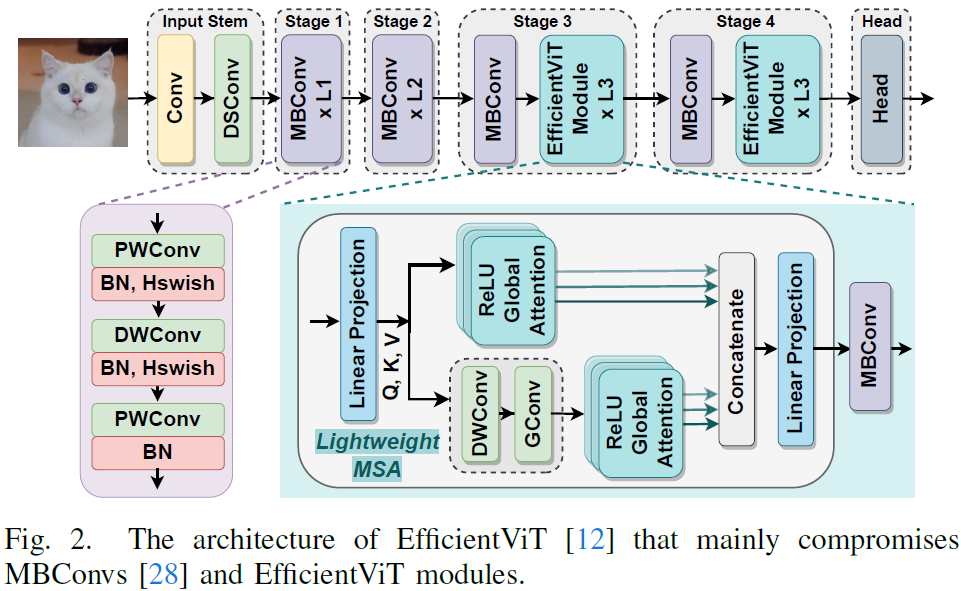
Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with \textit{standard ViTs}, we focus our attention towards the quantization and acceleration for \textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose \emph{Trio-ViT} accordingl......